
テーマ「多远回归模型」
今日で、統計学の授業も終了です。最後は、重回帰分析です。
- 振り返り。认知(認知)&预测(予測)の違いについて。认知は、モデルy=α+βxがあったとしたら、xとyは関係があるのか?そしてそれはどのようなモデルなのか?ということを理解すること。预测は、そのモデルをもとに、数値を予測すること。モデルの確証性は関係ない。
- Y=飲料売上は、X1=消費者収入、X2=飲料価格、X3=販促費用、X4=広告費用、X5=食品売上というYに影響を与える5つの因数を持つとする。X2のYに対する影響を考えるときに、X2がその他の因数Xに与える影響度を踏まえることを、控制变量と呼ぶ。
- YとXの関係を調べるためには、STEP1)相関係数を出す。STEP2)一元回归(単回帰)で係数を出す。STEP3)多远回归(重回帰)で係数を出す、というSTEPを踏む。
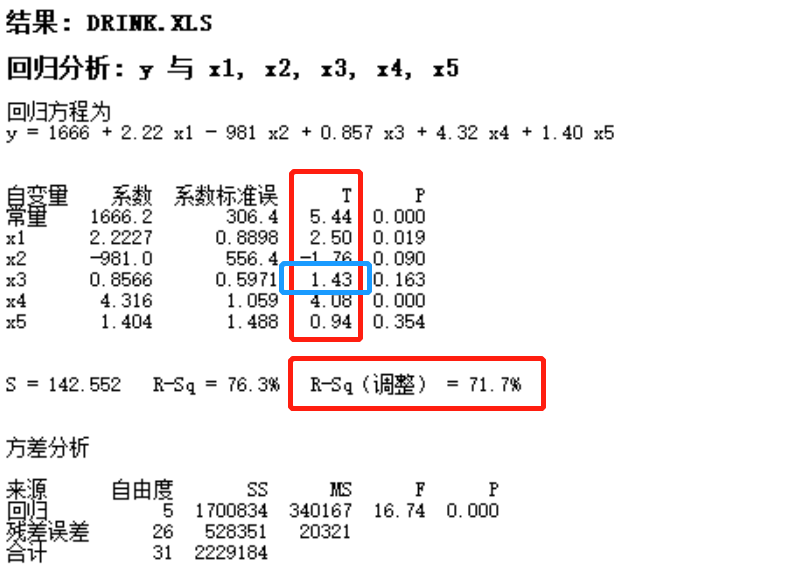
- minitabを使って、多远回归模型を出したときに、すべての因数Xを選択すべきか?どの因数を選択し、どの因数を拒否すべきか?R-Sqは因数動詞の関係を表すものではない。R-Sqを調整する必要がある。
- R-Sqは、SSR/SST=(SST-SSE)/SST=1-SSE/SSTとなる。これに調整を加える。SSE、SSTに自由度で割って調整する。 この調整はF検定。 F= 1-{SSE/(n-k-1)÷SST/(n-1)} となる。これは、R-Sqは、平方和の割合だったのに対して、方差(分散)の割合となる。※SSE、SSTはX1からXkまでの合計値だから、平方和。それに対して、調整(F検定)は、SSE、SSTに、Xの数から自由度を引いた数字で割っているので、分散となる。
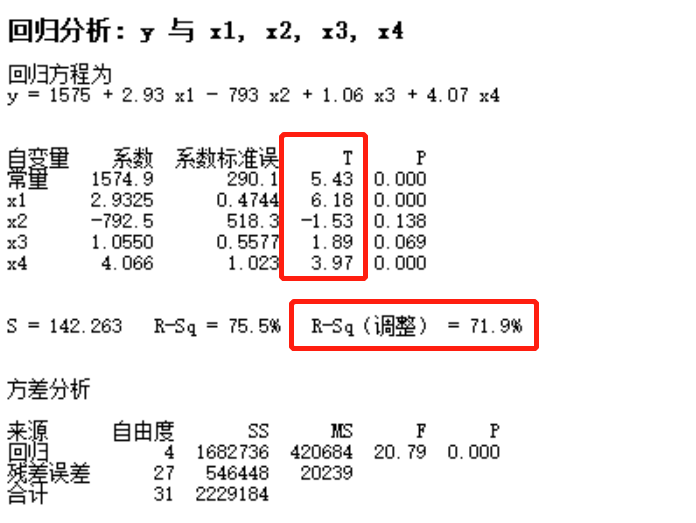
- そして、minitabで算出したR-Sq【調整】の高いモデルを採用する。また、因数は、t値を見て、1以下であれば、拒否する。条件削除前は、下記画像1参照(R-Sq71.7%)。削除後は、下記画像2参照(R-Sq71.9%)。
- なお、このR-Sq調整の回归方程の検定モデルは、F検定であるが、H0=β1=β2…=βk=0(つまり、Yに影響を与えない)とする。
- 次は、虚拟变量(Dummy Variable)。これは、数字を持たない男女、季節などを因数として組み込む時に使う。例えば、男:0、女:1と設定する。ただ、男女のように、選択肢が2つしかない場合は、問題ないが、季節のように、4つの場合、春:1夏:2秋:3冬:4と設定して良いかというとそうではない。季節の場合は、4つの変数を作る。春YS:1、春No:1、夏YES:1、夏NO:0など。注意点は、minitabで回帰分析をしたときに、回帰モデルから4番目の虚拟变量は削除される。それは、1-3番目の虚拟变量に4番目の要素が入っているからである。また、算出された虚拟变量の一番数字をゼロに戻す、つまり選択から外して、算出すると同様な虚拟变量を作り出すことが出来る。下記動画1参照
- 最後は再度、事例を使って確認。Vol:食品商品の売上高に対して、Promp:商品の平均単価、Feat:広告量、Disp:陳列割合の3つの変数があるデータがある。これをminitabで重回帰モデルを算出すると、LVOL = 17.2 – 0.956 PROMP + 0.0101 FEAT + 0.00359 DISPと出た。広告量と陳列割合が固定ならば、商品単価が上がると商品売上は落ちるということ。あと、この重回帰モデルが正しいのか、一般的な状況で考えてみる。陳列割合が増る→売上は上がる、広告量が減る→売上は下がる、陳列割合が増える→広告量は減る。これを立証するには、各相関係数を出せばよい。
- 最後に教授から。授業で学んだモデルはそのまま使えない。現在にあったモデルを作らないといけない。現在のビッグデータ時代、データはどんどん溜まる。だから、そのデータを統計学を使い、方向性を見出す。そして、AIは統計学を基に発展して、ビッグデータを支える。仏教の言葉とHuaweiの任正非のインタビューを紹介。下記画像3)と動画2)参照。
テストは2週間後なので、少し時間があきますが、しっかり復習して挑みたいと思います。
動画3)Huawei任正非のインタビュー、統計学の話は8分過ぎから。