テーマ「简单线性回归模型(単回帰モデル)」
- 単回帰モデルの数式は、y=f(x)+e、eは误差で、一つの参数。y=α+β・x+e
- xを自变量(independent variable)、yを因变量(dependent variable)と呼ぶ。
- 相関関数は、分散がわかるだけで、因数は分からない。
- 単回帰モデルで出力したy-hatと実際のyの差を、残差(Residual)と呼ぶ。
- このResidualを少なくすることで、最適な 単回帰モデルが求められる。
- そのためには、 y-hat(拟合值)と実際のyの差であるResidualを平方する、最小二乘法を使う。
- 単回帰モデルの各参数は、標本からきているので、母数との差が生じる(样本误差)。
- β-hatは、βの標本平均のこと。
- ピザ屋の周辺にある大学の生徒数xが、売上yに影響を与えるのかを、 単回帰モデルy=α+β・xで定義した時、本当にこのモデルが成り立つかを検証するには、βが0でない、ということを検定すればよい。
- つまり、検定の方法に則り、H0:β=0、H1≠0で設定。
- まずは、SE(β-bar)である标准误差を出す。そして、標準化の式で、t値を出す。
- t=(β-bar-0)/SE(β-bar)
- また、Nが少なく、t分布で知らべるときは、N-1ではなく、参数が2つ(α、β)あるため、N-2とする。また、このt分布は、双尾(両側検定)となる。
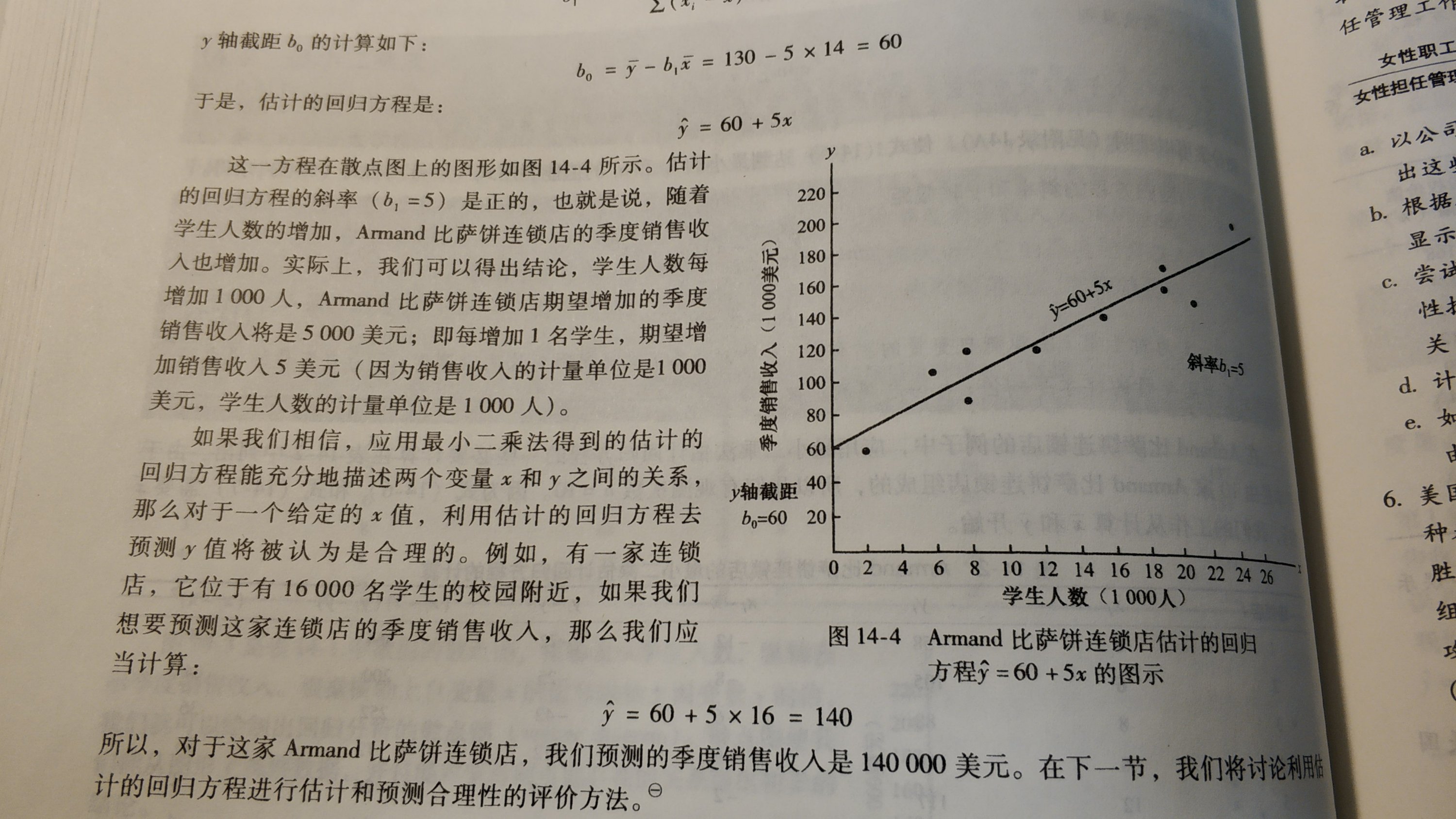
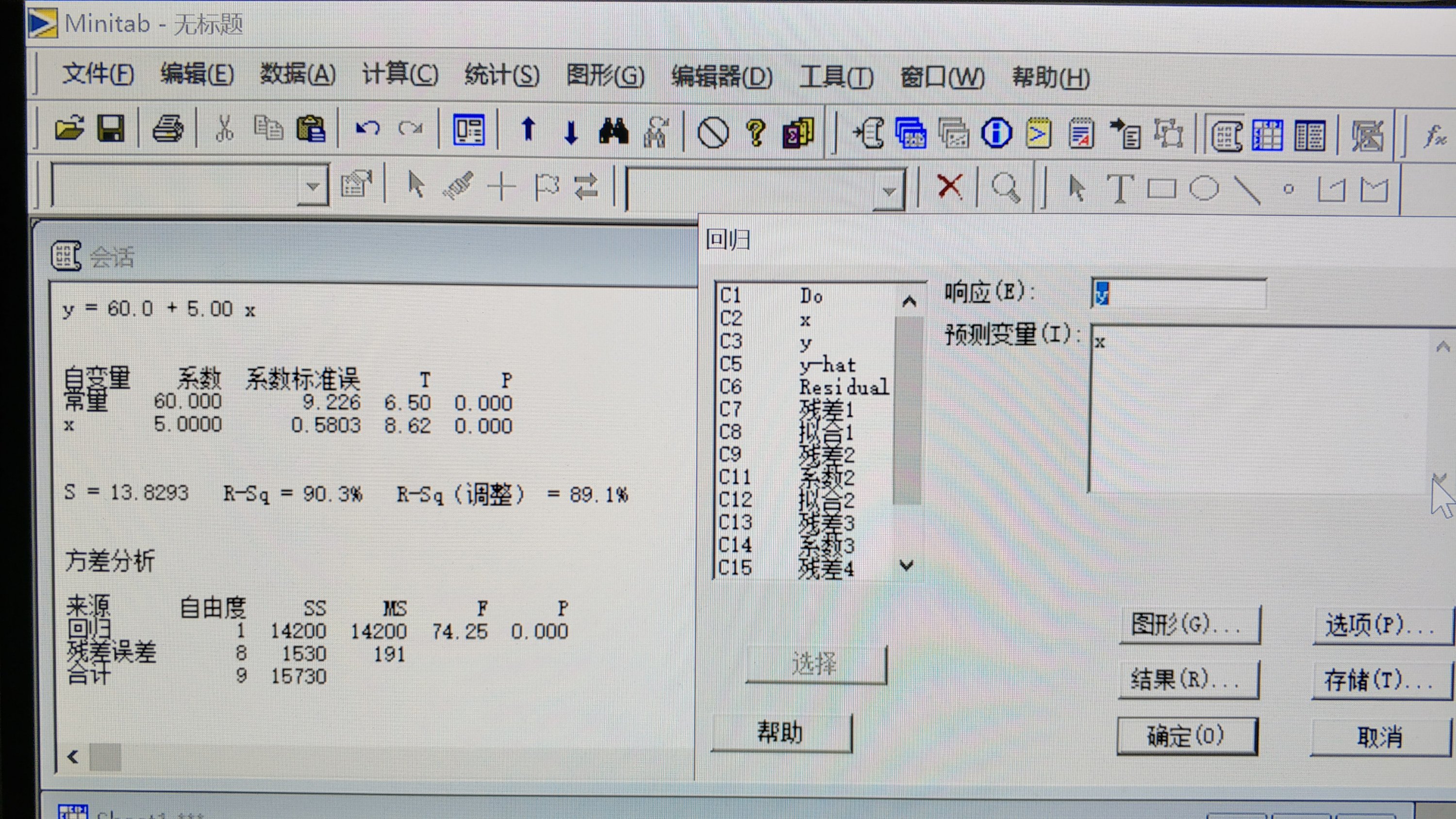
- 上記の 単回帰モデルを、N=10の時、y-hat=60+5.00xとすると、SE(β-bar)=0.58となり、t値が8.62であるならば、excelでTDIST(8.62,8,2)で計算すると、標準正規分布時は、0.002519%となる。
- ゆえに、p値は、0.002519%×0.58=0.00146102%と非常に小さくなり、第一类错误を犯す危険がない、つまりH0を拒絶することが出来る。
- 上記、大学の生徒数xとピザ屋の売上yおよび 単回帰モデルy-hatの相関関係を調べる。minitabの命令コマンドcorrを使うと、xとyの相関指数は、0.95。xと残差(residual,yとy-hatの差)の相関指数は、0.00。では、xとy-hatの相関指数は?答えは、1.0、一次直線のため。
- また、 残差(residual,yとy-hatの差) の平均値は0となる。
- 模型的目的是为了解释变异、 単回帰モデルの目的は、変化を説明すること。ゆえに、単回帰モデルの変数の範囲を定義するために、平方根を使う。
- 実際のデータと平均の差の平方根をSST( Total sum of squared )、 回帰モデルと平均の差の平方根を SSR(sum of squared residuals)、 実際のデータと回帰モデルとの平方根を SSE(sum of squared errors of prediction)と呼ぶ。式は、SST=SSR+SSE。SST、SSR、SSEの関係の参考資料はコチラ
- 上記の事例でいうと、SST(15,730)=SSR(14,200)+SSE(1,530) となり、SSR/SST=90.3%となり、この数値を、R平方(R-SquareもしくはR二乗)と呼ぶ。90.3%のxはy-hatと関係するが、残り10%はxとy-hatの関係性はないということ。R-Squareの参考資料。
- 例えば、住宅価格へ影響を与える要素のR-Sqを見たときに、房龄15%、面积68%となれば、これは、面积の方が、房龄よりも住宅価格に影響を与えているといえる。では、15%+68%=83%を房龄&面积で影響を与えていると言えるのか?No、なぜならば、おたがいに重複しt影響を与えている部分があるから。
授業中は、結構もやもやして聞いていましたが、こうやって整理して初めて分かったことが多かったです。。。もうすぐに次の授業が迫っているので、できるだけ予習しないとダメですね。