
テーマ「假设检验的基本思路(仮説検定の基本概念)」
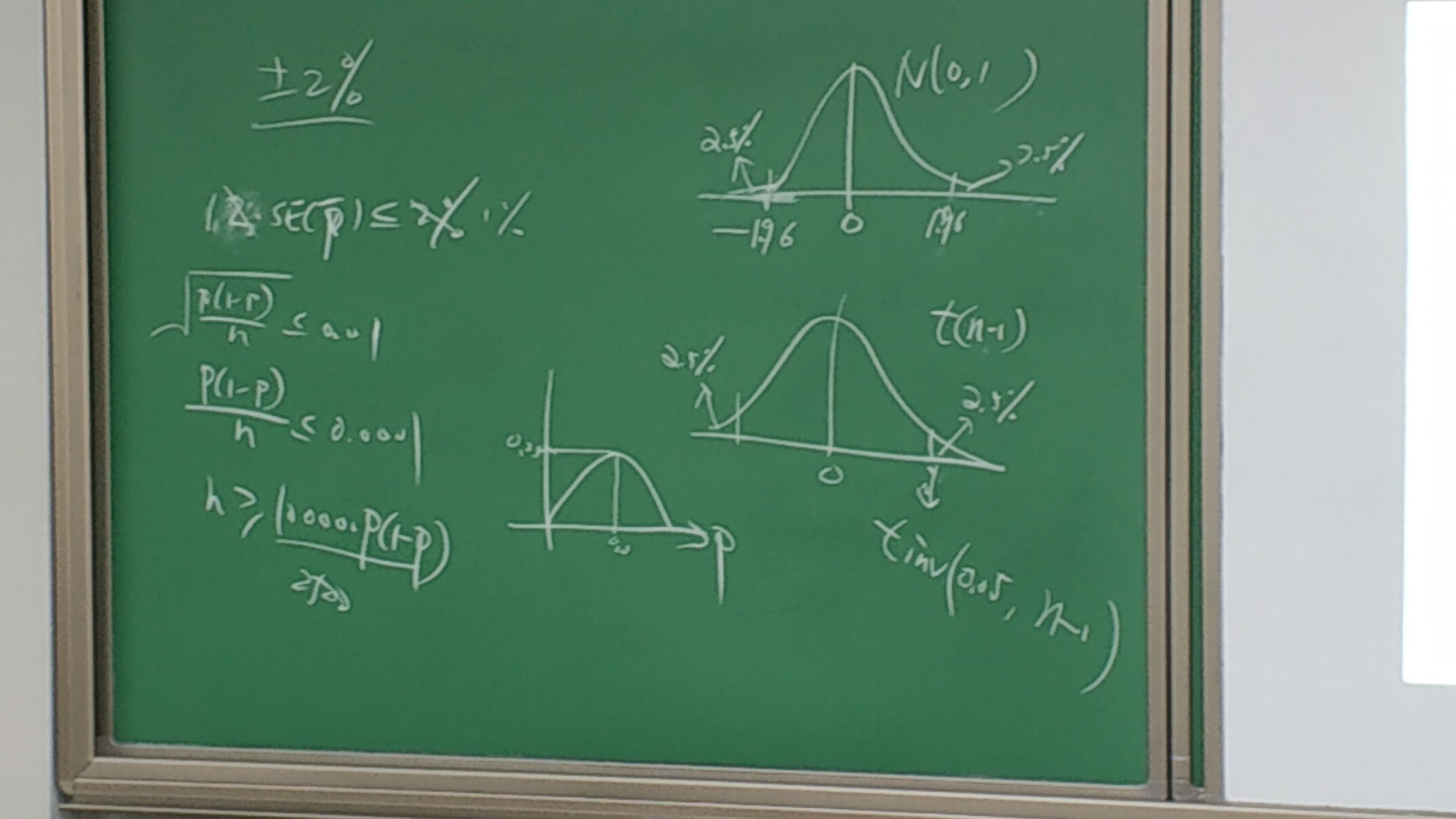
- 前回の振り返り
- 假设检验の基本概念は、H0:原假设(帰無仮説、null hypothesis) H1备择假设(alternative)。
- H0:原假设(null hypothesis) があっているにも関わらず、棄却される場合を、“第一类错误”。H1が正しいのだが、H0が選択される(つまり、H1が棄却される)ことを“第二类错误”、この2つの間違いを“两类错误”と呼ぶ。(ネイマンピアソン原則)
- H0には、棄却したい仮説、H1には、その反対の棄却したくない仮説を入れる。※とおもったいてが、中文の教科書は下記の通り。
- ※色々なデータを集めた研究の仮説に関しては、 H0には、棄却したい仮説、H1には、その反対の棄却したくない仮説 を設定。例えば、新開発したエンジンの性能が、旧来型エンジンの燃費 24㎞/ℓ よりも、良いかどうか? H0≦24㎞/ℓ H1> 24㎞/ℓ
- ※各データが真実であるという前提の場合、仮設検定を使って、このような仮説設定に異議を唱え、統計結果が仮定の不正確性を支持するかどうかを確定する。この場合は、H0に、正しいと思っている仮説を設定。H1には、その逆の仮説を設定。
- そして、第一类错误の発生確率の基準値を、”显著水平(有意水準、level of significant)”と呼ぶ。
- 事例1、今年のテレビ視聴平均時間は、N=60、標本平均X bar=14.5h、样本标准差3.8であった。では、来年は13.3hであると言えるか?
- 标准误差は、SE(X bar)=3.8/√60=0.49。14.5-13.3=1.2、ゆえに、1.2÷0.49=2.45。t分布のnormdist(2.45,0,1,1)*2で0.014、distを使うと、確率は、0.017でかなり小さい。
- この確率のことをP值(p-value)と呼ぶ。 第一类错误の発生確率のこと。 0.017は、第一类错误 の発生確率は低い、ゆえに、H0を棄却することができる。※この時のH0は、平均値が今年と来年の視聴率平均が”同じ”。
テーマ「基于双样本的检验」
- 2つの標本があるときの検定に関して。
- IPOした494社の各財務指標4点を集約して、STと非STの特徴を見つけたい。
- ST(グループ0)と非ST(グループ1)という2つのグループに分けて、4つの指標の違いがあるのか検証をする。
- H0:µ0=µ1、H1 :µ0≒µ1とする。H1が棄却されれば、H0成立となる。
- ゆえに、グループ0とグループ1の差のP值を求める。
- X bar0=0.29、X bar1=0.16とすると、0.29-0.16=0.13、これをグループ0とグループ1の标准误差の差を求めて、割る。
- グループ0とグループ1の标准误差の差は、2.85。このP値を計算すると、2*normdist=4.3%。平均からの距離が2.85±で離れ散るので、確率は2倍する。
- ワイン農作の事例、夏や冬の降水量など、4つの要因がワインの価格に影響する。
ということで、次回以降は、回帰分析にはいっていきます。今回は、授業の中で、「红楼梦」の前半後半で作者が異なっているのか、頻出単語で分析する、というような事例が紹介されました。その際に、「红楼梦」を読んだことがあるかと聞かれ、「ありません!」。その後、「源氏物語のようなものだよ。読んだことある?」と聞かれ、また「ありません」と答えました。その場では、「源氏物語」と聞かれたことが分からなかった。。。もちろん、読んだことはあります。先生がせっかく聞いてくれたのに、中国語が分からないという。。。頑張りましょう!

